
Herbold Fellow Kira Zeider Utilizes Machine Learning to Model Aerosol Behavior

Kira Zeider is a first-year graduate student in the department of Chemical and Environmental Engineering under the mentorship of Dr. Armin Sorooshian. She was selected as one of the five inaugural University of Arizona Herbold Fellows for her interest in big data as well as application of machine learning techniques to the NASA Aerosol Cloud Meteorology Interactions Over the Western Atlantic Experiment (ACTIVATE) campaign.
The mission of the ACTIVATE campaign is to determine interactions between clouds, meteorology, and tiny liquid or solid particles called aerosols in the marine boundary layer. The marine boundary layer is the part of the atmosphere that is in direct contact with the ocean, which is traditionally a difficult part of the atmosphere to study. This campaign is gathering data using two aircraft and remote sensing measurement devices with flights spanning over three years and resulting in approximately 600 flight hours and 150 flights for each airplane, generating one of the largest aircraft datasets ever obtained. Air quality and pollution significantly affect human, animal, and overall environmental health, so to understand this relationship, one piece to the puzzle is finding patterns within the aircraft dataset.
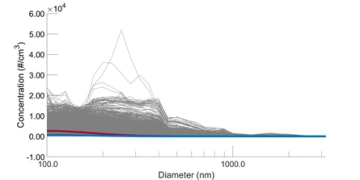
An example of a size distribution plot, where the x-axis represents the diameter of the particles in nanometers and the y-axis represents the number concentration of the aerosols (cm-3). The red and blue lines each represent a cluster, therefore the k-means value for this plot would be two. Since two clusters don’t describe this size distribution, the process would need to be run again with more clusters.
Big data is a field that focuses on synthesizing large and complex volumes of information, and machine learning is a technique to analyze that information. This technique consists of using computer algorithms that learn and improve through repetition and experience (i.e. feeding the algorithm different datasets from the same campaign).
Kira is working on using k-means clustering with aerosol size and volume distribution data to predict any patterns within the working dataset. These types of distributions match the size of aerosols (measured in the diameter of the particle, usually in nanometers or micrometers) to either their number concentration or volume concentration in the atmosphere. Clustering is a form of machine learning that finds groups of similar data points within a set and “clusters” them together, where “k-means” refers to the number of clusters. This method can take a high volume of data and extract a few characteristic patterns.
Kira believes this process will help inform NASA about the main sources of aerosols in the study region. For example, if the number concentration for a particular particle size is greater in a specific part of the atmosphere compared to other layers, the group can focus in on what mechanisms cause those particles to form and link it back to sources of those mechanisms. In December, Kira discussed her current efforts on KXCI’s Thesis Thursday (https://kxci.org/podcast/kira-zeider/).